Single-Shot Multi-Channel Convolutions in Free Space — Overcoming the SISO Optical Bottleneck
Prior optical accelerators were bottlenecked by single-channel mapping. A new architecture (arXiv:2606.07265) achieves true MIMO free-space convolutions using geometric spatial micro-organization and shared optical paths.
Paper: arXiv:2606.07265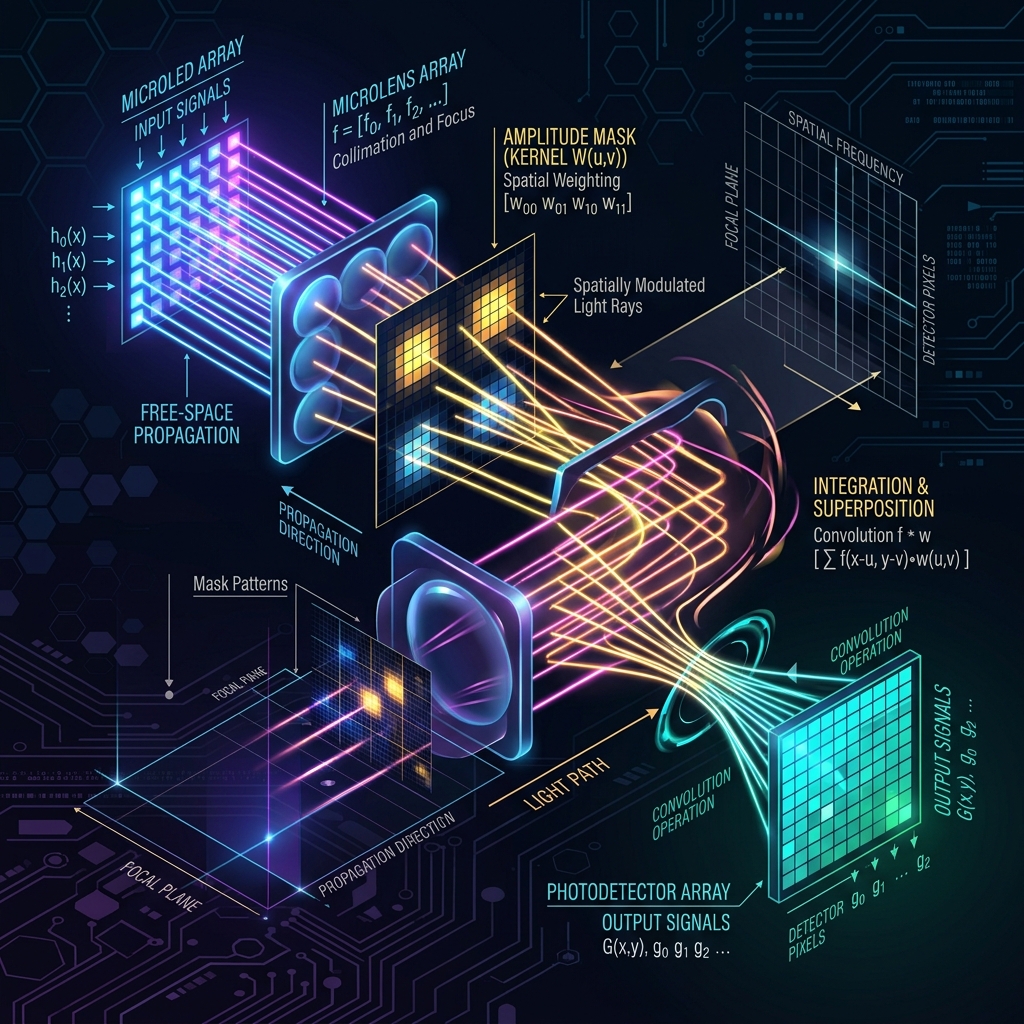
In modern deep learning, convolutional neural networks (CNNs) are heavily bottlenecked by memory transfer and data movement. While a single convolutional kernel is mathematically compact, convolving hundreds of input channels $n$ to yield hundreds of output channels $m$ across high-resolution spatial feature maps requires massive computational resources.
Optical computing accelerators—leveraging the physics of free-space light propagation—have long promised an escape hatch. By propagating light through lenses and spatial light modulators, linear operations can be executed at the speed of light. However, prior free-space architectures suffered from a critical structural flaw: they only supported Single-Input Single-Output (SISO) or Single-Input Multi-Output (SIMO) convolutions. Accelerating true Multi-Input Multi-Output (MIMO) layers required sequentially loading individual input channels, running the optical pass, and summing the partial outputs digitally. This hybrid strategy reintroduced the very data-transfer bottlenecks it sought to eliminate.
A new paper, "Multi-channel free-space optical convolutions with incoherent light" (arXiv:2606.07265), changes this landscape. The authors present a scalable, passive free-space design that computes true multi-channel convolutions in a single shot, requiring only a single Microlens Array (MLA) and an amplitude mask.
The Mathematical Formulation
In a standard convolutional layer, each output channel $O_j$ is defined by summing the spatial convolutions across all input channels $I_i$ with their corresponding kernels $K_{ij}$:
To map this operation onto a single optical path, the authors tile $n$ input channels across a 2D plane of incoherent light emitters (such as LEDs or VCSELs). Light from these emitters passes through a microlens array ($sp_{\text{MLA}}$) and onto a shared amplitude mask (an LCD panel) that displays the entire grid of convolutional kernels ($K_{ij}$).
To prevent the overlapping of light beams and ensure that light from adjacent pixels hits the correct kernels, the system enforces a strict geometric constraint relating the microlens spacing $sp_{\text{MLA}}$, the emitter spacing $sp_{\text{LE}}$, and the magnification factor $M$:
The physical configuration splits the optical propagation into three distinct stages:
- Emitter to Microlens ($d_1$): Set to the focal length of the microlens ($d_1 = f$).
- Microlens to Mask ($d_2$): The collimated beams propagate a distance proportional to the magnification ($d_2 = f(M - 1)$), producing a grid of spots on the kernel mask with spacing $sp_{\text{K}} = sp_{\text{MLA}} \times M$.
- Mask to Sensor ($d_3$): The modulated beams propagate a distance $d_3 = fM$, projecting onto the photodetector array.
To achieve a convolution stride of 1 where output spacing matches input spacing ($sp_{\text{PD}} = sp_{\text{LE}}$), the propagation distances must balance:
Validation: Simulation vs. Experiment
The authors analyzed and validated their design using a multi-tiered pipeline:
| Evaluation Phase | Methodology | Pearson Correlation ($r$) |
|---|---|---|
| Geometric Ray-Tracing | Monte-Carlo sampling of uniform-angle emission models | 0.902 |
| Diffraction Simulation | Rayleigh-Sommerfeld wave propagation with random phase fields | 0.954 |
| Experimental Setup | Projector + scattering mask, Thorlabs MLA, Holoeye LCD | 0.762 (vs. Sim) / 0.820 (vs. GT) |
In their physical prototype, they mapped 4 input channels (using MNIST digits scaled to $8 \times 8$ pixels) onto 4 output channels through $3 \times 3$ kernels. The experimental results yielded an average correlation of 0.82 against ground-truth digital convolutions, demonstrating the viability of the spatial layout despite ambient noise and alignment tolerances.
Why This Matters for Co-Processors
This design stands out because it shifts the complexity from active electronics to passive, micro-structured geometry. There is no active routing in the middle of the system. Instead, the microlenses steer the light passively, and the physical superposition of different wavefronts landing on the same photodetector pixel performs the sum-reduction across channels for free.
By substituting the prototype projector array with custom high-density microLED or VCSEL arrays, this architecture can scale to hundreds of parallel compute channels, offering a high-throughput, low-latency foundation for next-generation optical coprocessors.